An overview of deep learning in music generation
Music, for a long time in human history, was just spicy wiggly air that travelled into your ears. You hit something, it made noise. Hit a bunch of stuff in a pattern, there you go, a beat. But as much as I love caveman funk, human beings have a tendency to keep inventing things.
So, along came circuits. In the late 19th century, a bunch of people decided to make musical instruments that worked not by blowing air into bamboo sticks, but instead by ...wait, connecting to a power socket??? Much to the chagrin of their neighbours, this sparked the birth of what we today call as electronic music, leading to more music being made with transistors and more teenagers dressing in all black.
But there was a problem. Analog wasn’t cool enough. We needed more. And so people thought, “hey, wouldn’t it be really cool if we had software that could digitally make music?”
A common format for computers and instruments to talk to each other was developed, called MIDI. It had a bunch of advantages —
- Size: A saved MIDI file is basically just text. Therefore it’s much smaller than an audio file, which is sampled thousands of times a second.
- Change instruments: A MIDI file only describes which notes to play. You could send the note data to any instrument you wanted to use.
Now that we had built virtual instruments, people started to focus on ways to control them. The most common software was called the DAW — Digital Audio Workstation, aimed at consumers and normal music producers. Plenty of computer musicians emerged, creating and composing in their bedrooms what earlier required a full studio and orchestra.
But at the far realms of the esoteric, a bunch of cool weirdos decided to bypass the DAW’s graphical user interface and to instead write music through raw direct code. This led to the development of programming languages like ChucK and Sonic Pi (a variant of Ruby).
Okay, so what about deep learning?
We have virtual instruments, we have methods to digitally write music, but at the end of the day there needs to be a human to actually write it.
But what if there needn’t be?
Just kidding.
Unless?
Since all a MIDI file is is a bunch of notes stored as text data, it was just a matter of time until somebody went into their shower one fine morning and thought to themselves, “hey, deep learning can already work with text data, can’t it work with music data as well?”
Spoiler alert: yes.
LSTMs
Ever since Andrej Karpathy came out with his “The Unreasonable Effectiveness of Recurrent Neural Networks” blog post, people have been going around applying RNNs to anything they could lay their hands on. Soon, LSTM models trained on music note sequences started floating around on Github.
At this point, let’s do a quick rundown of what those words mean. Traditional neural networks start thinking from scratch. This is obviously stupid in some cases, so they invented Recurrent Neural Networks — which are basically neural nets with loops in them. A loop allows information to be passed from one step of the network to the next.
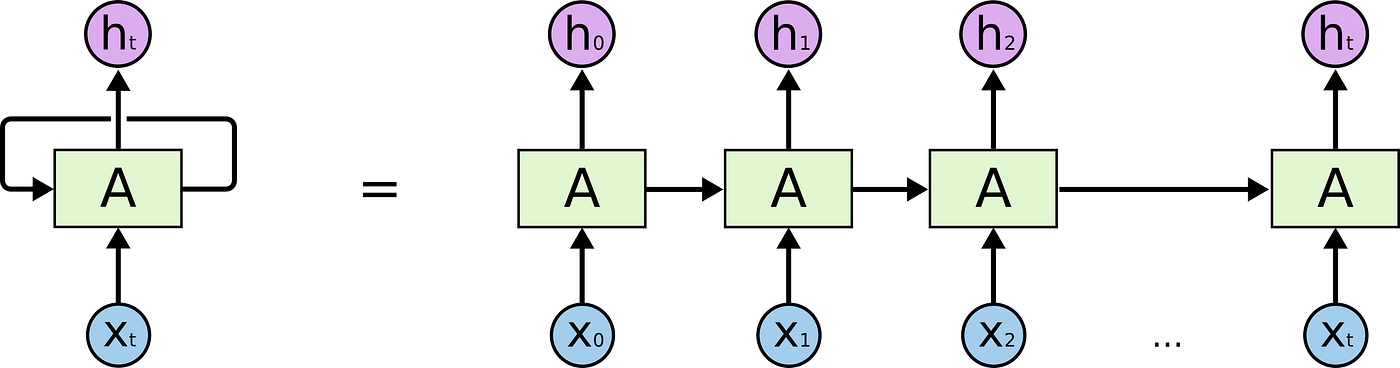
This neural network is quite loopy (hahaha).
Now, we have a neural network that can theoretically remember things from previous data, but it turned out they couldn’t effectively remember things that were really far back. A Long Short Term Model is a special kind of RNN aimed at solving this problem, by tweaking the architecture a bit and adding stuff like gates and increasing the layers to four from one. Science, bro.
Anyway, how do you actually make music with LSTMs? Nice try. It says ‘overview’ in the title of this post, so here’s the overview:
- Get a bunch of MIDI data.
- Clean them, convert them, and one-hot encode them.
- Train the model.
- Generate.
Here is a detailed tutorial in case you’re into that kind of thing.
Embedded below is the output from the above tutorial. You’ll notice that it doesn’t sound too shabby, but then again might be cherry-picked results.
GANs
If you’re one of those people who hang out at the intersection of art and technology, you would’ve heard about this one. Used mostly for working with images, Generative Adversarial Networks (you know you’re in trouble when your mom calls you by your full name) are actually a fun idea.

In a GAN, there’s a Generator and a Discriminator. The former generates an image. The discriminator tries to predict if it’s a generated image or an original one, and passes on that information to the generator.
We can think of the generator as being like a counterfeiter, trying to make fake money, and the discriminator as being like police, trying to allow legitimate money and catch counterfeit money. To succeed in this game, the counterfeiter must learn to make money that is indistinguishable from genuine money, and the generator network must learn to create samples that are drawn from the same distribution as the training data. — NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
Eventually, after epochs of listening to feedback from the discriminator, the generator finally learns how to make something.
Now here’s the part where things get interesting. You could combine RNNs with adversarial training (called a C-RNN-GAN), feed it our usual note sequence data and therefore get a MIDI output. This is what these madlads who used GANs to generate Pokémon style music did.
Spectrograms
But since GANs are usually used to work with images, instead of using the notes of songs, what if you trained it on the spectrogram of the audio?
Teacher: you can’t hear pictures. Me:
A spectrogram is one of many ways to visualize sound, or in our case, convert sound data into an image. And you could therefore train GANs on the image version of the music we want it to learn from.
Waveforms
The same people who had this idea also had another idea. Instead of messing around with note data or making an image representation of the audio, why not just simply use raw audio waveforms itself?

They did it, and it’s called WaveGAN.
Our experiments demonstrate that — without labels — WaveGAN learns to produce intelligible words when trained on a small vocabulary speech dataset, and can also synthesize audio from other domains such as drums, bird vocalizations, and piano. — Adversarial Audio Synthesis, 2019.
To hear examples of the generated output, visit here.
Transformers
“Yeah, all this has been cool but like uhhh which one’s the latest one?”
The Transformer architecture is a recent advance in NLP, which has produced amazing results in generating text. Transformers train faster and have much better long term memory than previous language models. Give it a few words, and it can continue generating whole paragraphs that make even more sense than this one.
Since Transformers, like LSTMs, work with text data, we can simply use our old trick of using MIDI note data.
To make your own, here’s a good four part tutorial series to follow.
Conclusion
Is generation the only thing you can use deep learning in music for?
Nope. Artificial Intelligence techniques have found a bunch of use-cases in the music industry, one of the most important being sample organisation. Most musicians and producers work with samples, which are basically audio recordings of something — like drums, or the sound of a raindrop, a bottle cap opening and so on, depending on how creative they want to get. They collect and download hundreds of samples onto their computer, planning on using them in their projects someday, but when the time comes it’s hard to find the right sample without waddling through the clutter. However, now with autonomous audio classification and tagging, it becomes much easier for artists to explore their saved collection of samples by organising them based on predicted labels or cosine similarity and t-SNE.
Why are people generating music with deep learning?
A culture’s music is influenced by all other aspects of that culture, including social and economic organization and experience, climate, access to technology and what religion is believed. — Wikipedia
Throughout history, human beings have been making music. While we started with our own voice, we’ve been making other instruments ever since, from animal bones with holes to Moog modular synthesizers. As we evolve, so does how we make our music. Deep learning researchers playing around with music right now is similar to how early computer scientists played around with music on those big bulky machines. Heck, in 1956, Alan Turing was trying to play notes on his computer at the University of Manchester. We’re currently living in an age in which artificial intelligence is one of the most important topics. The fact that it is seeping into art and music is therefore not surprising; merely a sign of the times.
Or as Kanye said:
I’m living in the future so the present is my past